
Revisiting Missing A-B Matches - Thu, 18 Jan 2018
I’ve been working away the past couple of months to finish off Version 2 of Double Match Triangulator. There’s lots of major improvements, and I’m hoping to find ways to get it to do some of the analysis for you as well.
What Double Match Triangulator does differently than other DNA matching tools, is that it uses not just the segment matches that one person has, but uses the segment matches of two people together. Let’s call yourself Person A, and the one you’re matching with Person B. Double Match Triangulator compares the the segment matches Person A has with other people to the segment matches Person B has with other people. Any that overlap are called a Double Match.
For example, Person A matches Person C on Chromosome 1 from position 72017 to position 7238701. Person B matches Person C on Chromosome 1 from position 3528942 to position 12148559. They Double Match between positions 3528942 and 7238701.
The magical thing about this Double Match is that now we just can look in Person A’s matches to see what segment matches he has with Person B (or we can look in Person B’s matches since both will show the same matches with each other). If Person A matches Person B over some part of the Double Match segment with Person C, we have a triangulation: Person A matches Person C, Person B matches Person C, and Person A matches Person B – all over the same segment.
If Person A and Person B don’t match, we have what I call a Missing A-B match. We still have the Double Match of Person A with Person C and Person B with Person C.
You would think a Double Match that does not triangulate should just be considered a random match. I can match someone, and you can match the same person but we don’t have to be related. I can be a cousins of Person C on their dad’s side and you can be a cousin on their mom’s side.
But when using Double Match Triangulator, we are choosing the B people to be people who we, Person A match to. With Person B being a DNA relative, the Double Matching of Double Match Triangulator is more powerful than the matches you see lining up on the same segment in a Chromosome Browser. In the Chromosome Browser, you have no indication of whether the people lining up with each other are related to each other or not. But in Double Match triangulation, you are picking the B people that are related to you. It is like using a Chromosome Browser where you are just including people that are guaranteed to be related to each other. That’s one of the things that makes Double Matching so useful. Of course the other thing is that Double Matching will find in one fell swoop EVERY TRIANGULATION that two people have between them.
The important thing about a triangulation is that all IBD (Identical By Descent) segments that are passed down from a common ancestor must triangulate. By looking only at triangulating segments, you are eliminating many segments that are false (guaranteed not to be IBD) and increasing your chance of finding IBD segments.
If we didn’t match to Person B, then none of the Double Matches would triangulate and en we are no better than using a Chromosome Browser and verifying the Person B-C matches one by one.
Back to the Missing A-B match
Unless you Double Match, you won’t find any Missing A-B matches. When looking in a Chromosome Browser as Person A, you’ll find Person B and Person C that overlap. You’ll then find out from either Person B or C if they match the other person on that segment and if they do, they triangulate. If they don’t, then you have a Missing B-C, but that is not a missing with you, Person A.
By Double Matching, all the B-C matches are verified in advance. If Person A also matches Person B, then you have a triangulation. If not, you have a Missing A-B match.
Missing A-B matches therefore are Person A matching Person C and Person B matching Person C but Person A not matching Person B on the same segment but with the important caveat that you also know that Person A and Person B are related, and they match and triangulate on other segments, but not this one.
Missing A-B matches are not triangulations. Therefore they cannot be IBD. So what possible use then can they have?
It took me a while to figure this out. In fact I was going to take the display of Missing A-B matches out of Version 2 of DMT and I even took all the code out of the program that displayed them. But after doing some more work, I realized they were important, and put that all back in.
What got me thinking was the number of Missing A-B matches there were. There were often as many if not more Missing A-B matches than there were triangulations.
When I last puzzled over this, about six months ago in my Triangulation and Missing a-b Segments article, I came to the conclusion that Missing A-B matches could point to a common ancestor. But the way I had figured it, I thought that it required the parents of Person C to be both descendant from the same common ancestor or ancestor pair in these two possible configurations:
But I never really thought that either of these two scenarios would be so plentiful to give so many missing A-B matches. Maybe in a endogamous population. But in my test runs even non-endogamous populations are loaded with Missing A-B matches. So what gives?
I finally figured out another case. Here are some results from a run of DMT using close relatives:

Here we have a daughter as Person A, double matched with her Uncle as Person B, who is her mother’s brother. They match each other between 72017 mB and 7238701 mB shown on the Base AB line.
On the next line, the daughter of course will triangulate with her mother and her uncle because the daughter half-matches her mother everywhere, and her mother matches her uncle because it is the mother who passed down that segment to the daughter. Therefore they triangulate over that segment. That segment came from the common ancestor who would be the grandparent who passed that segment down to the uncle, the mother and the daughter.
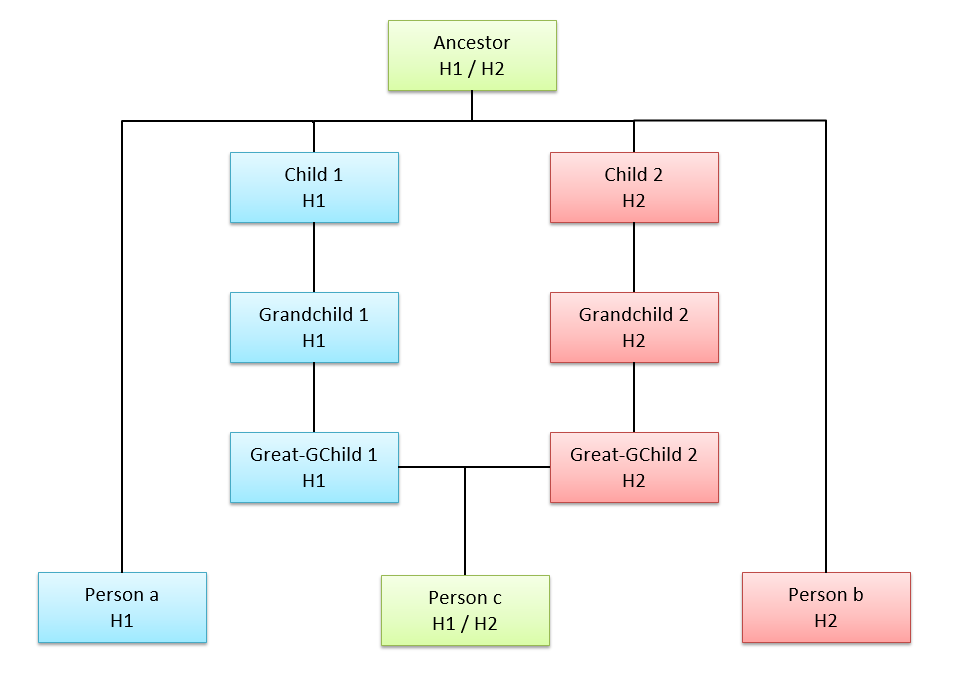
On the third line, we pick the brother of the daughter as Person B. The daughter we already know matches the uncle on that segment. And her brother does as well. They Double Match. But the brother does not match his sister on that segment. What happened in this case is that mother passed down the other grandparent’s segment to the son. Mother still matches the son, but the son and daughter have different grandparent segments from their mother. The brother matches his uncle on the other grandparent’s segment. This is a Missing A-B match. The diagram looks like this:

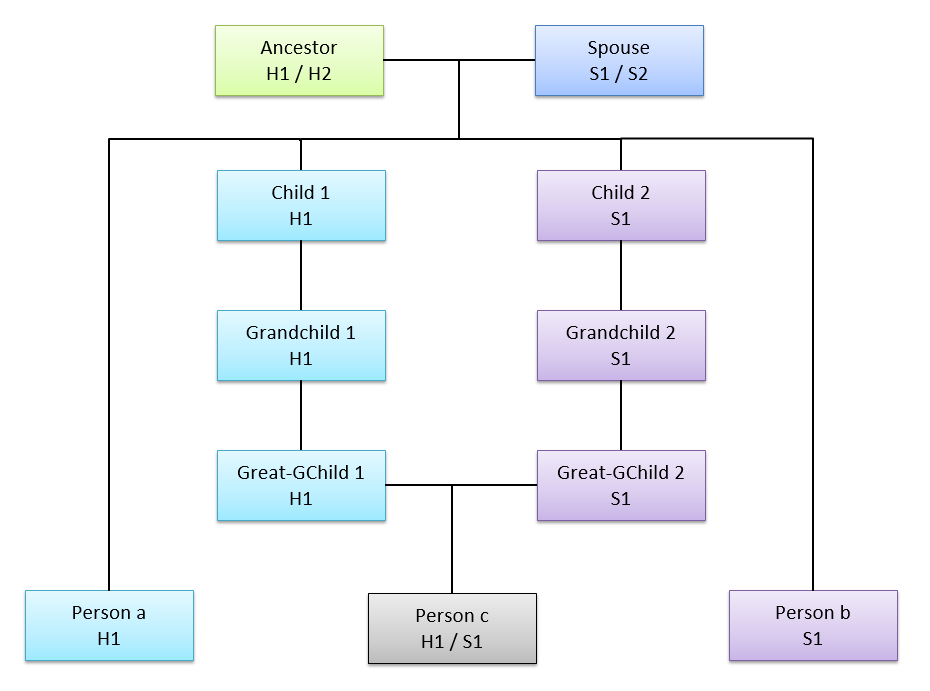
This can happen at further relationships as well. For example at first cousins, we can have Cousin 1 as Person B who triangulates with the daughter and the uncle (Person C), and Cousin 2 who as Person B still double matches but doesn’t triangulate because he has a missing A-B match, as shown in the 4th and 5th lines of the spreadsheet above.
The diagram illustrating this cousin situation is:

Person A, the daughter matches her uncle on H1 and her Cousin 1 on H1. Her brother and Cousin 2 both match her Uncle on S1. The daughter matches Cousin 1 on H1 but does not match her brother or Cousin 2.
So we have a situation here where a Missing A-B match occurs that is not caused by having parents related and descendant from a common ancestor as I had surmised in my previous article. This new situation is likely much more common and is probably the reason why there are so many Missing A-B matches.
In fact, it can happen with further relationships than 1st cousins. Here’s an example with a 2nd cousin and 3rd cousin as Person B resulting in a Missing A-B match with the daughter as Person A and the uncle as Person C.

And just so you don’t think that Person B or Person C necessarily have to be a close relative of Person A, they can be close relatives of each other instead. For example below, the Son is Person A, the 3rd Cousin is Person B, and the Uncle of the 3rd Cousin is Person C:

’This does require that whoever is Person C, receives both the common segments, one from each parent, so that it has one that matches both Person A and Person B .
The bottom line is that a Missing A-B match is indicating that Person C who matches both Person A and Person B could have a common ancestor with Person A and Person B. The common ancestor would have passed a segment down to Person C and also to either Person A or Person B.
What’s important to understand out of all this is that, although they are not IBD to Person A, Missing A-B matches may still be indicate the possibility of a common ancestor with Person C and they should not be ignored.

 Feedspot 100 Best Genealogy Blogs
Feedspot 100 Best Genealogy Blogs




